2026-03-10
Handling Dynamic Shared Memory in Postgres
How PostgreSQL evolved from static shared memory to DSM/DSA, and what changed with the DSM registry in modern releases.
Before delving into PostgreSQL 17+, it is useful to build a mental model for how the server organizes files, handles processes/backends, and uses shared memory.
The Database Cluster and File System
The OS account that owns the cluster is usually a postgres user. In Postgres.app setups, it often defaults to the current user library path.

Historical Note
- Berkeley Postgres (ancestor of PostgreSQL) used the term
baseas shorthand for "data-base". - So
base/became the location where each database stores its files, and that naming remained in modern PostgreSQL.
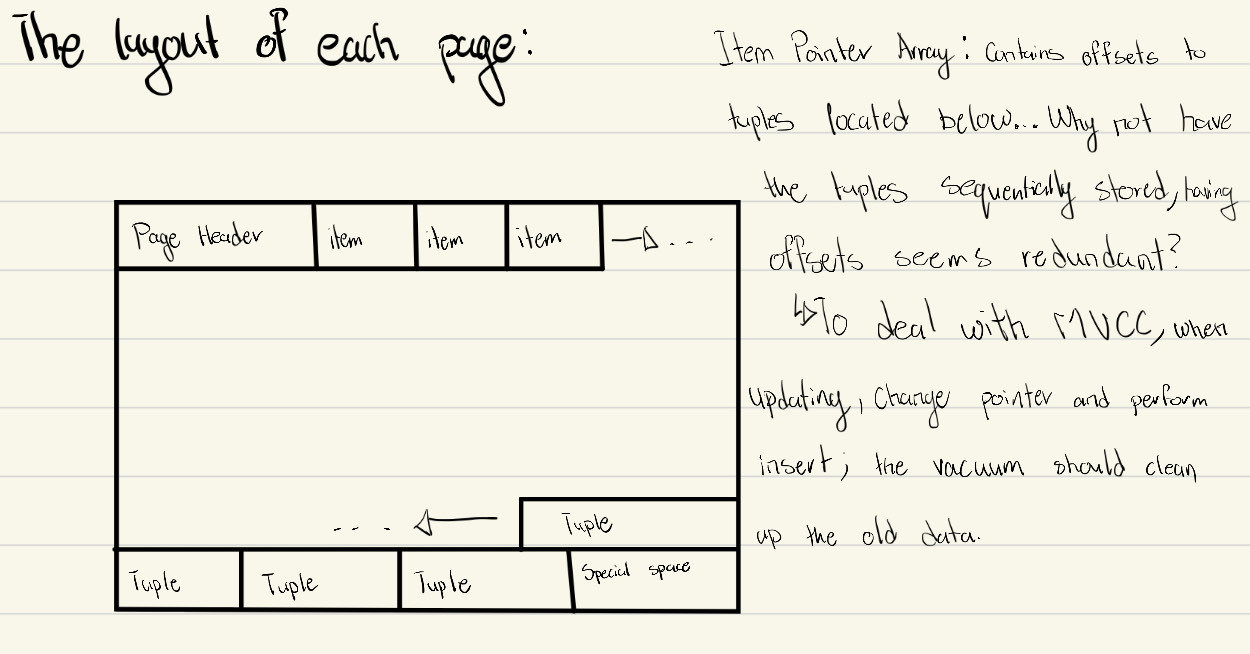
Page Layout
Each page contains metadata in a page header, followed by item pointer arrays that reference tuple offsets for row data.
- Think:
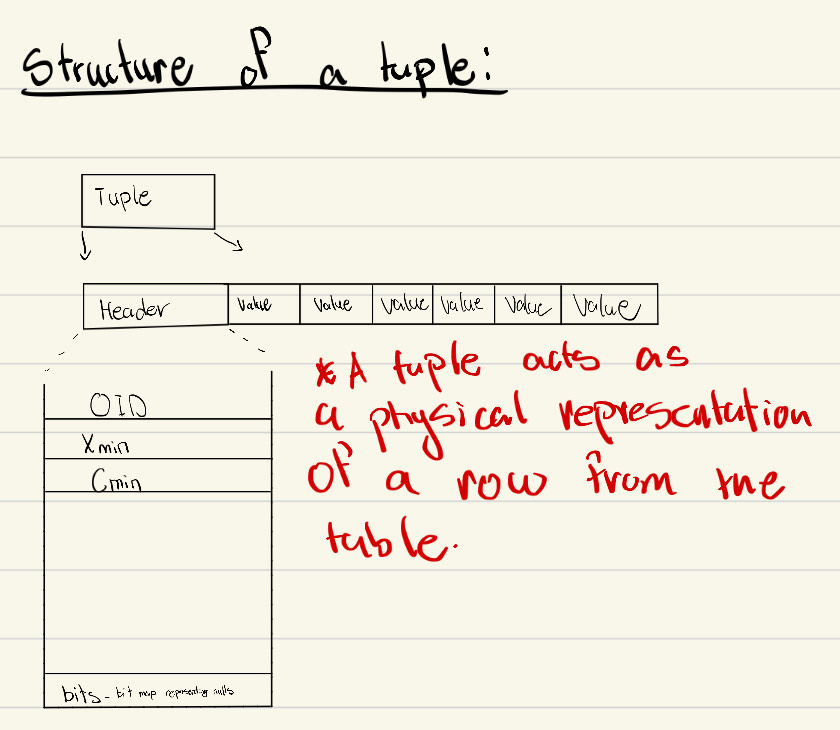
Table -> Item offset -> Tuple. - A tuple effectively holds a single row's data from the target table.
Pointers (offsets) are critical for update semantics. In PostgreSQL MVCC-style behavior, updates create new row versions rather than in-place overwrite, which is why pointer/tuple organization matters.
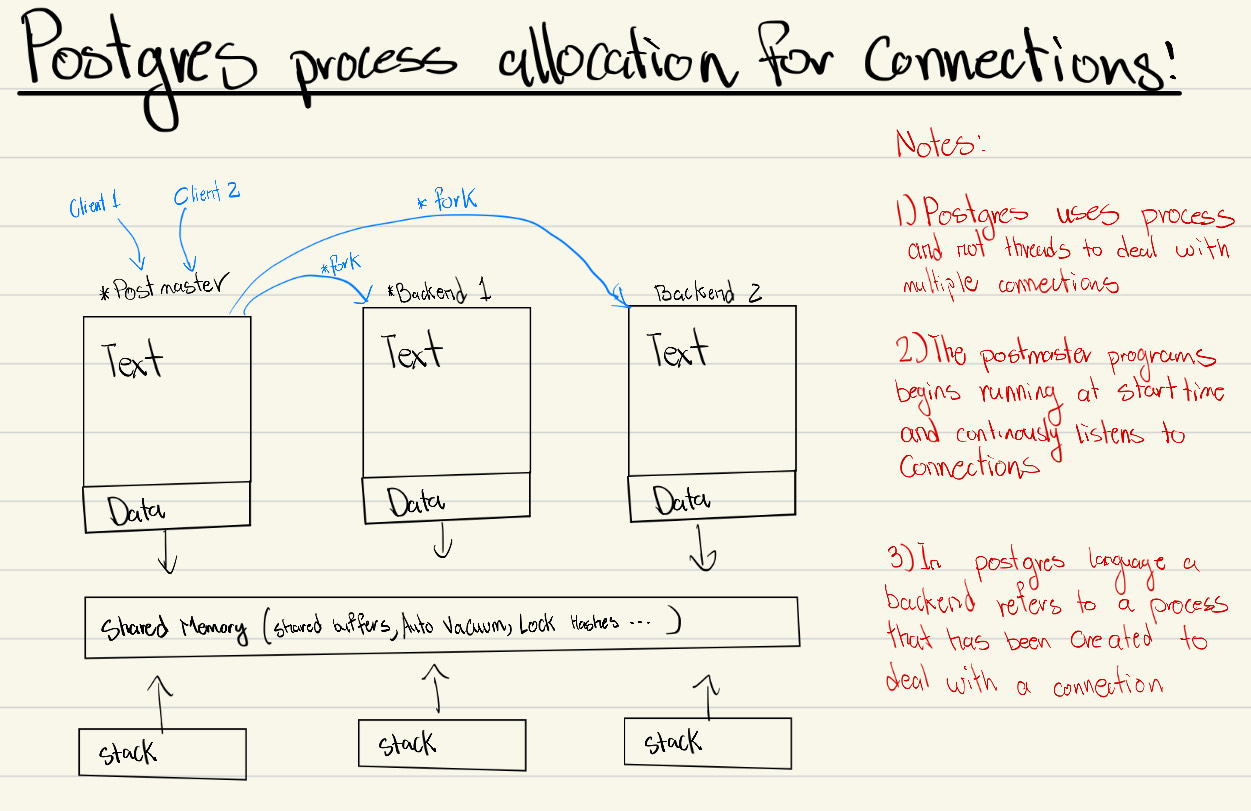
Process Allocation Model
PostgreSQL is process-based. During startup, the postmaster runs and waits for connections. For each connection it forks a backend process that attaches to shared memory (shared buffers, autovacuum coordination, lock structures, and related internal state).
- Backend: effectively the forked process context created from postmaster for a new connection.
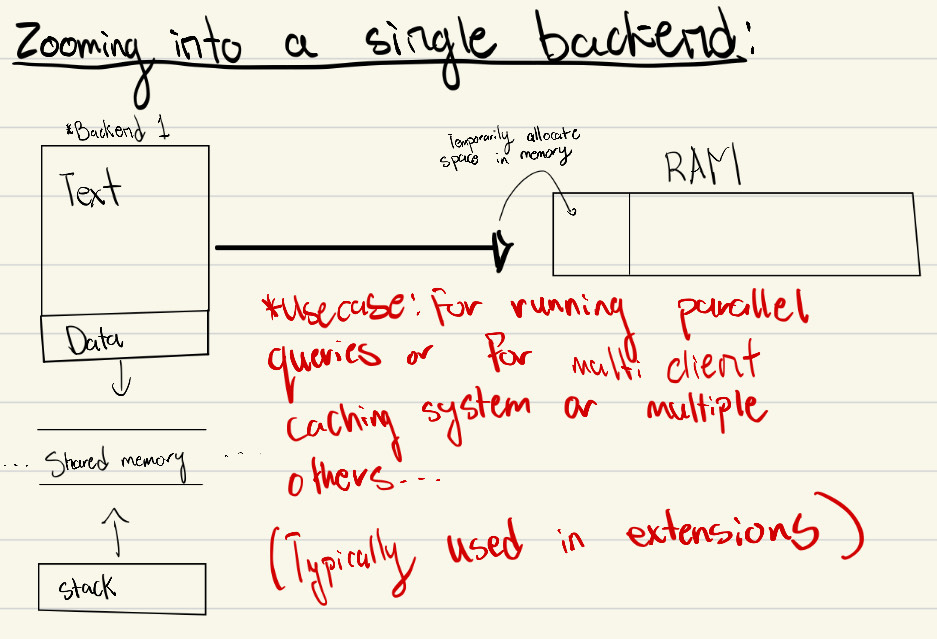
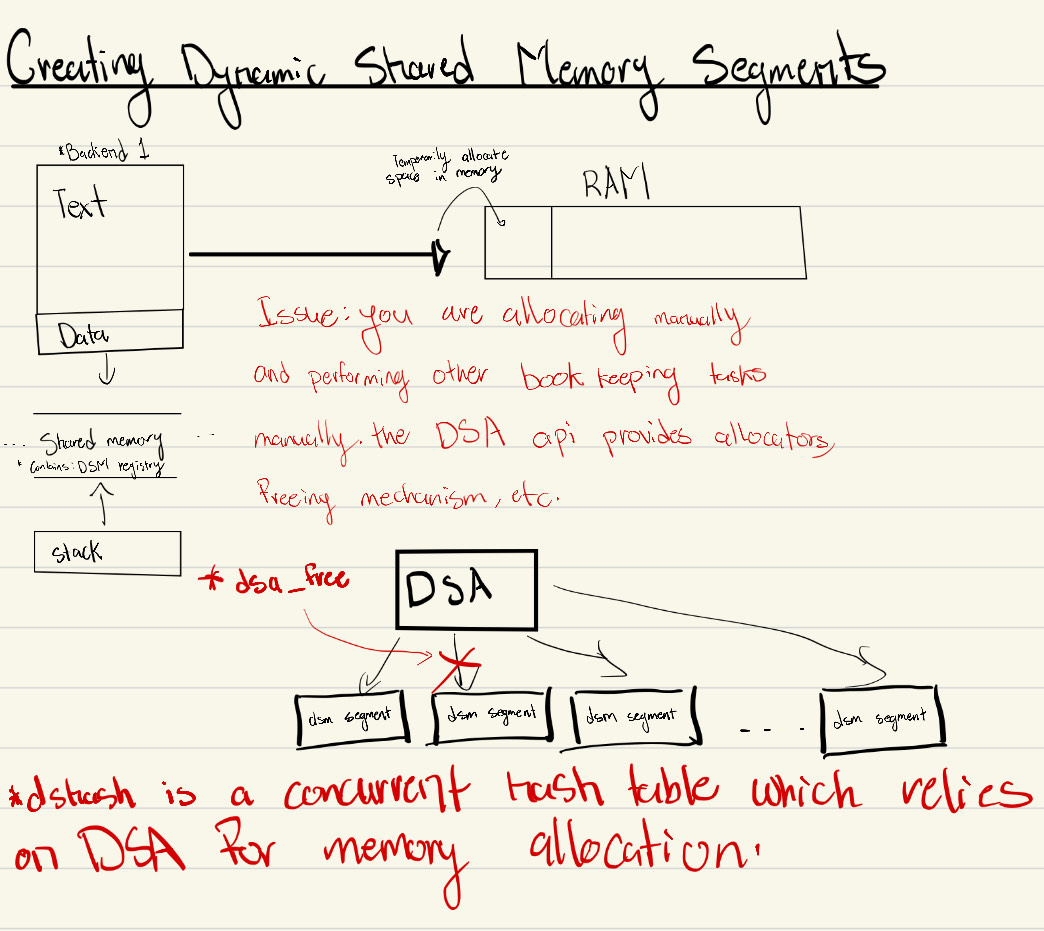
Dynamic Shared Memory (DSM)
Before DSM, the core shared memory model was static. PostgreSQL 9.4 (2014) introduced Dynamic Shared Memory so backends could allocate temporary shared RAM at runtime.
This was particularly useful for:
- parallel query execution
- extensions needing cross-backend shared state
DSM Registry and DSA Evolution
DSM solved static-size limits, but introduced discoverability issues: once a segment was created, other backends needed reliable ways to discover and attach to the right objects.
In modern PostgreSQL development (including PostgreSQL 17 era work), the DSM registry was introduced to track active DSM allocations under string names. That enables lookup/attachment by other backends and improves lifecycle visibility.
A second challenge was managing data structures inside DSM segments. Dynamic Shared Areas (DSA) address this by providing allocator-like APIs analogous to malloc()/free() via dsa_allocate() and dsa_free().
Once DSA existed, shared structures like dynamic shared hash tables (dshash) became easier to standardize.
Key APIs/features discussed in this line of work include:
GetNamedDSMSegment()- proposed/related named helpers like
GetNamedDSA()andGetNamedDSHash() - visibility via system view
pg_dsm_registry_allocations
References
- Bruce Momjian, Inside PostgreSQL Shared Memory (YouTube, 2013): https://www.youtube.com/watch?v=Nwk-UfjlUn8
- Nathan Bossart, Introduction of the DSM Registry (pgsql-hackers thread): https://www.postgresql.org/message-id/20231205034647.GA2705267%40nathanxps13
- Thread view: https://www.postgresql.org/message-id/flat/20231205034647.GA2705267%40nathanxps13
- Florents Tselai, Inspecting DSM Registry Allocations (2025): https://tselai.com/pg-dsm-registry-allocations
- PostgreSQL commit (DSM registry): https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=8b2bcf3f2